Visibilité IA dans l'auto : arrêtons les études one-size-fits-all
Pourquoi les baromètres de visibilité IA du secteur automobile ne servent à (presque) rien — et ce qu'il faudrait mesurer à la place.

Le problème de fond
Posez la question “révision Peugeot 208 prix” à ChatGPT, Perplexity et Gemini.
Faites-le maintenant, avant de lire la suite. Comparez les trois réponses.
Vous constaterez 3 choses.
- Premièrement, aucun des trois moteurs IA ne cite les mêmes sources.
- Deuxièmement, les constructeurs automobiles — ceux que les baromètres sectoriels s’efforcent de classer — sont quasiment absents des réponses.
- Troisièmement, les acteurs réellement cités (centres auto, forums, comparateurs indépendants, médias) ne figurent dans aucune étude de visibilité IA du marché automobile.
Cette simple expérience résume le problème fondamental des “baromètres IA” qui se multiplient dans le secteur automobile depuis fin 2025.
Le cycle des études de visibilité anxiogènes
Le mécanisme est désormais classique.
Une agence multi-sectorielle ou un éditeur d’outil de tracking produit une étude suffisamment spectaculaire pour générer de l’anxiété (”vous êtes invisible sur l’IA !”), mais suffisamment vague pour ne jamais remettre en question sa propre méthodologie.
L’objectif premier n’est pas la rigueur analytique — c’est la captation de leads de directeurs marketing dans le secteur automobile.
Le dernier exemple en date : le “Baromètre Auto” publié conjointement par Uplix et Meteoria (octobre 2025 - janvier 2026).
575 prompts envoyés à ChatGPT, 1 classement des constructeurs par taux de visibilité, et 1 conclusion sans surprise : les marques les plus connues sont les plus citées, avec Toyota en tête à 47,5%.
L’étude n’est pas mauvaise en soi — le design est soigné, certaines observations sont pertinentes, et la distinction entre positionnement SERP et positionnement LLM est pédagogiquement utile.
Mais elle souffre de 3 biais structurels qui la rendent inutilisable pour quiconque cherche à prendre des décisions réelles.
Biais n°1 : 1 seul LLM ne raconte qu’une fraction de l’histoire
L’étude Uplix/Meteoria interroge exclusivement ChatGPT.
Or, selon une analyse de Yext portant sur 6,8 millions de citations (octobre 2025), les trois principaux LLM ont des comportements de citation structurellement différents :
- Gemini fait confiance à ce que dit la marque : 52% de ses citations proviennent des sites propriétaires des marques.
- ChatGPT fait confiance à ce qu’internet agrège : 49% de ses citations proviennent de sources tierces (annuaires, comparateurs, agrégateurs).
- Perplexity fait confiance aux experts sectoriels et aux avis utilisateurs : 24% de ses citations proviennent de sources de niche (forums spécialisés, annuaires verticaux).
Une étude Qwairy de 118 000 réponses IA confirme l’ampleur de la divergence : seulement 11% des domaines cités sont communs entre les plateformes.
ChatGPT, Google AI et Claude retournent la même liste de marques dans moins de 1% des cas.
Autrement dit, une étude mono-LLM est, par construction, aveugle à 89% du paysage de citations.
Le tableau ci-dessous, compilé à partir des données Qwairy (Q3 2025), illustre à quel point les plateformes ne puisent pas dans le même corpus :
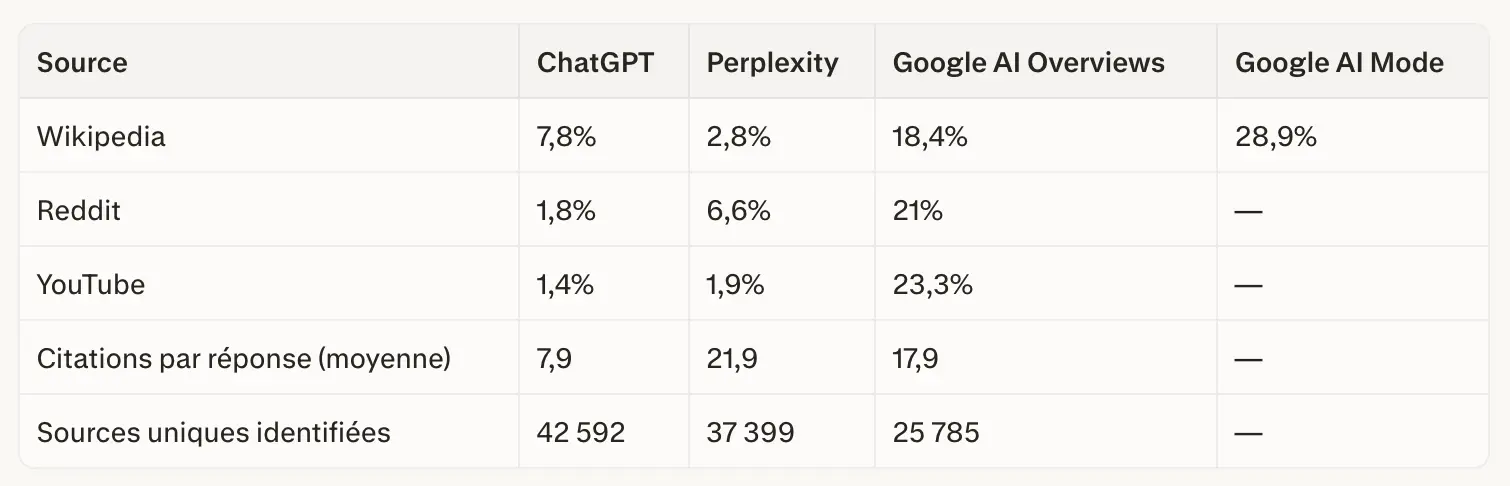
Biais n°2 : Les prompts sélectionnés gonflent mécaniquement les résultats
La méthodologie Uplix/Meteoria l’admet elle-même en page 3 : les prompts ont été “sélectionnés manuellement pour refléter les intentions où les marques sont le plus souvent citées.”
C’est un aveu de biais d’échantillonnage.
Quand on choisit des requêtes pour leur propension à citer des marques, on obtient mécaniquement des taux de visibilité élevés.
Le taux de 52% de visibilité globale annoncé par l’étude n’est pas représentatif des requêtes automobiles réelles — c’est le reflet d’un jeu de prompts pré-sélectionné pour produire des résultats spectaculaires.
Pedro Dias (Visively) formalise ce problème avec précision : “Un score de visibilité dérivé d’une liste de prompts mal construite n’est pas une mesure de la réalité du marché. C’est une mesure de la performance sur ce jeu de test spécifique.”
Pedro Dias ajoute que la sensibilité au phrasé des prompts est telle que de petites différences de formulation peuvent changer entièrement si le modèle s’appuie sur des sources web, récupère d’autres documents, ou répond depuis ses connaissances mémorisées.
Biais n°3 : Confondre notoriété et performance AEO / GEO
Toyota domine le classement à 47,5% de visibilité.
Mais Toyota n’est pas visible parce qu’elle a une stratégie AEO / GEO — elle l’est parce qu’elle est l’une des marques les plus documentées de l’histoire d’internet.
Des centaines de milliers de pages Wikipedia, de fiches techniques, d’articles de presse, de comparatifs indépendants et de discussions Reddit mentionnent Toyota dans pratiquement toutes les langues.
La corrélation n’est pas la causalité.
Et l’analyse de Seer Interactive sur 10 000 questions soumises à GPT-4o le confirme : les mentions de marque dans les réponses IA corrèlent davantage avec le volume de mentions existant sur le web qu’avec une quelconque stratégie d’optimisation.
Selon Ahrefs, cité par RankScience, les mentions de marque sont 3 fois plus prédictives de la visibilité IA que les backlinks.
Le classement du baromètre Uplix est donc, pour l’essentiel, un classement de notoriété web — pas un classement de performance GEO / AEO.
Et c’est précisément ce qui le rend inutile pour les acteurs qui ne sont pas des constructeurs automobiles.
L’automobile n’est pas un secteur, c’est un écosystème
Traiter “l’automobile” comme une verticale homogène, c’est comme traiter “la santé” comme un seul marché.
Un neurochirurgien et une pharmacie de quartier n’ont pas les mêmes enjeux de visibilité — un constructeur automobile et un centre auto non plus.
Le baromètre Uplix/Meteoria promet en page 2 de s’adresser à six profils distincts : constructeurs, services et réparation, marché de seconde main, réseaux de distribution, agences marketing, équipementiers.
Mais l’étude ne délivre qu’un classement de constructeurs automobiles.
C’est comme proposer un “baromètre de la santé” qui ne classerait que les laboratoires pharmaceutiques, en ignorant les hôpitaux, les pharmacies, les mutuelles et les médecins de ville.
Voici ce que chaque profil métier devrait réellement mesurer — et pourquoi aucun baromètre généraliste ne le fait.
A. Les constructeurs automobiles (OEM)
Leur enjeu IA : être cités comme référence dans les requêtes d’achat génériques (”meilleure voiture électrique familiale 2026”) et les comparaisons de gamme.
Ce que les études mesurent : exactement ça.
Donc pour les constructeurs, les baromètres actuels ont une utilité partielle — à condition d’élargir à plusieurs LLM.
Ce que les études ignorent : la qualité de la citation.
Selon l’étude Uplix elle-même, être cité “en dernier avec un ‘mais’” est presque pire que de ne pas être cité du tout. Le taux de visibilité brut (47,5% pour Toyota) ne dit rien sur la tonalité, le contexte, ni la position dans la réponse.
Le vrai concurrent IA de Renault n’est pas forcément Peugeot — c’est peut-être Dacia sur la requête “voiture électrique pas chère” ou Hyundai sur “SUV électrique rapport qualité-prix.”
KPI pertinent : score de positionnement qualitatif — être cité en premier, dans un contexte positif, avec des données chiffrées.
B. Les réseaux de distribution (concessionnaires VO / VN)
Leur enjeu IA : être cités sur des requêtes géolocalisées quand un acheteur cherche où concrétiser son achat.
Ce que les études mesurent : rien qui les concerne. Aucun baromètre ne teste des prompts comme “meilleur concessionnaire Toyota à Lyon” ou “avis sur les concessionnaires Peugeot de la banlieue ouest de Paris.”
Pourquoi c’est critique : selon CarGurus (décembre 2025), 36% des acheteurs utilisant l’IA s’en servent pour consulter les avis sur les concessionnaires.
C’est un usage massif, directement lié à la conversion — et totalement absent des baromètres.
L’étude Adpearance (octobre 2025) confirme : 25% des acheteurs auto en 2025 utilisent ChatGPT pour comparer des concessionnaires, et ce chiffre monte à 40% parmi les futurs acheteurs.
Leur levier GEO : avis Google structurés, contenu local, présence dans les annuaires de confiance, données schema.org de type LocalBusiness.
Les six types de schema indispensables pour un concessionnaire automobile sont LocalBusiness, Vehicle, FAQPage, Article, Service et Review.
KPI pertinent : taux de citation sur des requêtes géolocalisées à intention de confiance (”meilleur concessionnaire [marque] à [ville]”).
C. Les plateformes de véhicules d’occasion (VO)
Leur enjeu IA : être recommandées quand un utilisateur demande “où vendre ma voiture” ou “meilleur site pour acheter une clio 5 d’occasion.”
Ce que les études mesurent : des requêtes d’achat neuf et de comparaison entre constructeurs — un jeu dans lequel les plateformes VO ne participent pas.
Ce qu’il faudrait mesurer : les requêtes à intention transactionnelle orientée service.
Selon CarGurus, 40% des utilisateurs IA l’utilisent pour rechercher des annonces et 39% pour résumer les avis sur les voitures.
C’est le terrain de jeu naturel des plateformes VO — La Centrale vs Aramis vs Vendezvotrevoiture vs BYmycar.
Leur levier GEO : les comparatifs indépendants, les avis vérifiés, la présence sur les forums de consommateurs.
Perplexity, qui favorise les sources communautaires (6,6% de ses citations viennent de Reddit), est un canal critique pour ces acteurs.
KPI pertinent : taux de mention dans les réponses à intention “vendre” ou “acheter VO”, position dans la liste des plateformes recommandées.
D. Les réseaux de centres auto (Midas, Norauto, Feu Vert, Speedy, Euromaster, AD…)
C’est le profil le plus mal servi par les études existantes — et paradoxalement celui où l’enjeu GEO / AEO est le plus immédiat.
L’étude Uplix/Meteoria indique elle-même que 40% des requêtes sont liées à l’entretien et à la maintenance !
C’est le cœur de métier des centres auto. Mais aucun baromètre ne les positionne sur ces requêtes.
Les prompts qui les concernent sont ultra-contextualisés :
- “révision Peugeot 208 1.2 PureTech 100 à 60 000 km que faire”
- “climatisation Renault Clio recharge coût”
- “vidange Golf 7 quelle huile”
- “pré contrôle technique Lyon pas cher”
- “changement courroie de distribution Clio 4 prix”
Ces requêtes ont une forte intention commerciale locale.
Elles ciblent un service précis, pour un véhicule précis, dans une zone géographique précise.
C’est l’exact inverse des requêtes génériques sur lesquelles les baromètres testent la visibilité des constructeurs.
Leur levier GEO : des contenus FAQ ultra-spécifiques par marque et modèle, des pages de services structurées avec données chiffrées (prix indicatifs, durée, fréquence), et surtout des données schema.org de type Service et FAQPage associées à une structure LocalBusiness.
Selon Search Engine Land (mars 2026), les données structurées agissent désormais comme un signal de confiance pour les systèmes IA : quand les informations sont incohérentes, l’IA exclut l’entité plutôt que de risquer une réponse incorrecte.
Le marché français de l’aftermarket pèse 14,5 milliards de dollars en 2025 selon Grand View Research.
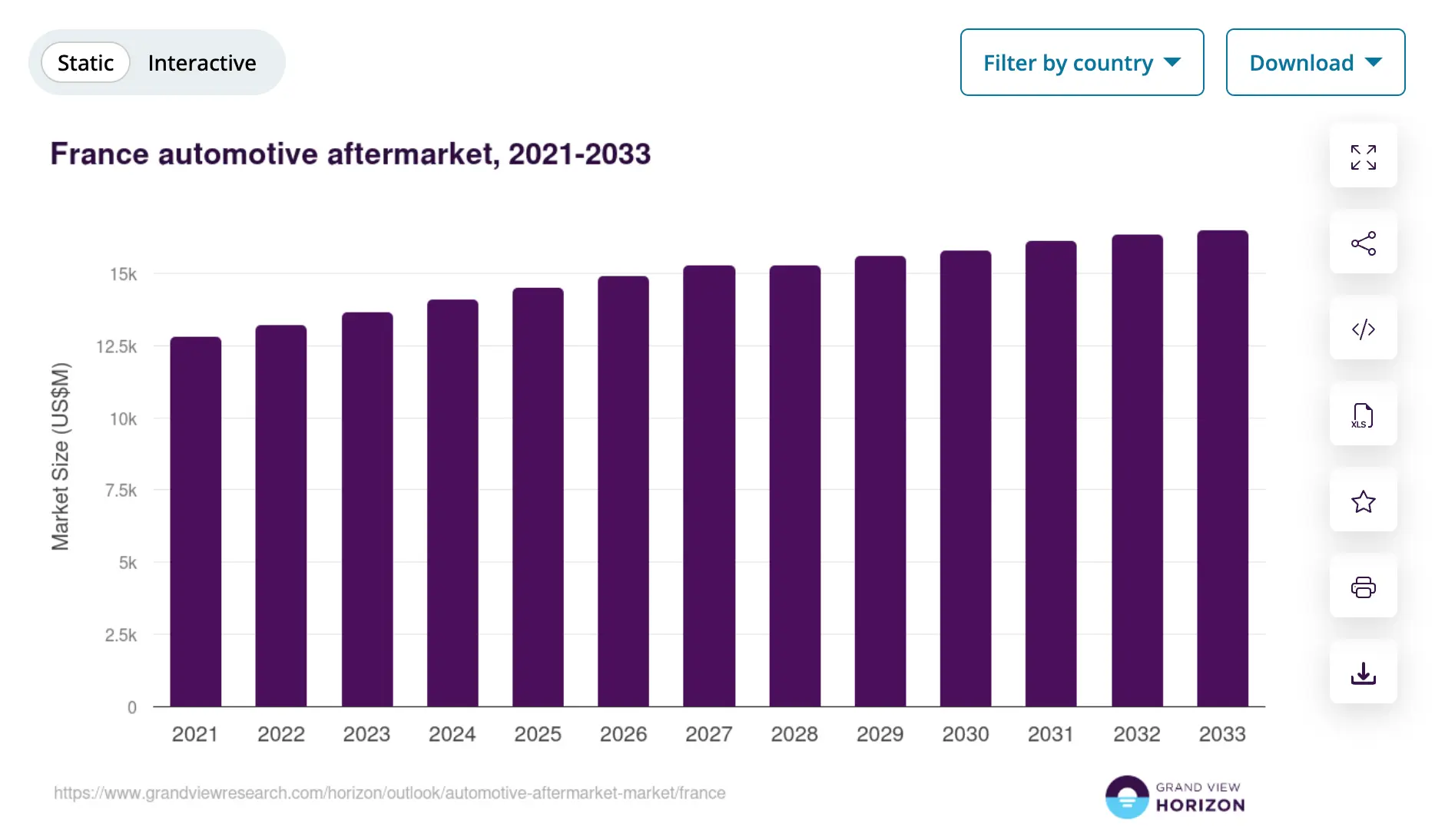
C’est un marché massif, porté par le vieillissement du parc automobile et le renforcement des normes de contrôle technique — et dont la visibilité IA n’est mesurée par personne !
KPI pertinent : visibilité sur des trigrammes “service + marque + modèle” dans un rayon géographique défini.
E. Les équipementiers et fournisseurs de pièces détachées
Profil quasi inexistant dans les études sectorielles, alors que le marché B2B et B2C des pièces détachées est structurellement lié à l’automobile.
Leurs requêtes cibles :
- “quelle batterie 12V pour Renault Zoe ?”
- “référence filtre à huile Citroën C3”
- “quand changer les plaquettes de frein Golf 8 ?”
- “comparatif des plaquettes de frein Brembo et TRW”
Le rapport Kahn Media “Shifting Gears” (juillet 2025) apporte un éclairage essentiel : seulement 1 à 2% des recherches aftermarket commencent aujourd’hui sur ChatGPT, mais 50% des achats finaux se font sur Amazon.
L’IA n’est pas encore le canal principal de découverte pour les pièces, mais quand elle le deviendra, les requêtes seront ultra-techniques.
L’article PCFitment confirme cette spécificité : les recherches automobiles sont fondamentalement différentes des autres secteurs.
Elles se structurent autour de la compatibilité véhicule (Year-Make-Model), des numéros de pièce OEM, des recherches par symptôme (”bruit de grincement au freinage”) et des filtres techniques multicouches (cylindrée, boîte de vitesses, motorisation).
Leur levier GEO : les données techniques structurées (compatibilité, références OEM), les guides d’installation, les contenus de comparaison prix/qualité — exactement ce que les LLM peuvent extraire et synthétiser.
KPI pertinent : taux de citation sur des requêtes de compatibilité et de diagnostic par marque/modèle.
F. Les médias et comparateurs automobiles
Profil oublié mais essentiel : les médias (Auto-Moto, Caradisiac, L’Argus, Le Blog Auto) et les comparateurs sont en réalité les principaux bénéficiaires indirects des études de type Uplix.
Ce sont eux que les LLM citent en source quand ils répondent à des requêtes de comparaison entre constructeurs.
Selon l’analyse Profound sur 680 millions de citations, les domaines .com représentent plus de 80% des sources citées par ChatGPT, et les sites .org (dont Wikipedia) comptent pour 11%.
Les médias spécialisés entrent dans cette catégorie de sources “d’autorité” que les LLM privilégient.
Ce que cela révèle : le baromètre Uplix mesure en réalité la performance des sources intermédiaires, pas celle des acteurs économiques qui achètent l’étude.
Quand ChatGPT cite Toyota à 47,5%, il cite en fait des articles de Caradisiac, des fiches L’Argus et des pages Wikipedia qui mentionnent Toyota.
Le constructeur est l’objet du discours, pas l’auteur.
Synthèse : qui devrait mesurer quoi
Le tableau ci-dessous croise les usages IA identifiés par les études CarGurus, Ekho et Cars.com avec les profils métier concernés.
C’est une grille qui n’existe dans aucune étude sectorielle — et c’est précisément ce dont les décideurs ont besoin.

La maturité du prompt, variable oubliée de tous les audits
Avant de mesurer la visibilité d’une marque ou d’un acteur, il faut cartographier les prompts par niveau de maturité décisionnelle de l’utilisateur.
Envoyer 575 prompts sans cette classification revient à mesurer la température d’une pièce avec un thermomètre placé au hasard.
Pourquoi la formulation du prompt change tout
Les données sont sans ambiguïté.
Selon OWDT citant des données Pew Research et Semrush :
- Les recherches de 1 à 2 mots ne déclenchent un résumé IA que dans 8% des cas.
- Les requêtes de 10 mots ou plus déclenchent un résumé IA dans 53% des cas.
- Les recherches sous forme de question déclenchent un résumé IA 60% du temps.
- La requête moyenne sur Google AI Mode fait 7,2 mots, contre 4,0 mots pour une recherche Google classique.
- Les prompts ChatGPT font en moyenne 70 mots.
Ce que cela implique : à mesure que l’utilisateur monte en maturité décisionnelle, ses requêtes s’allongent, se contextualisent, et déclenchent des comportements de réponse IA fondamentalement différents.
Un audit qui ne segmente pas par niveau de maturité est structurellement aveugle.
Le framework en 4 niveaux de maturité
Niveau 1 — Découverte / Éveil du besoin
L’utilisateur ne sait pas encore ce qu’il veut. Il explore un univers.
Exemples de prompts : “quelle voiture choisir pour une famille de 4”, “électrique ou hybride en 2026”, “budget moyen berline neuve en France”
Acteurs concernés : principalement les constructeurs et les médias/comparateurs.
Enjeu AEO : être cité comme référence générique, avec un positionnement positif. Le LLM agit ici comme un conseiller de confiance — selon Forbes citant une étude Cornell, le trafic généré par des interactions de type ChatGPT convertit jusqu’à 9 fois mieux que la recherche conventionnelle, précisément parce que les LLM fonctionnent comme des conseillers de confiance plutôt que comme des moteurs de recherche.
Volume estimé dans un audit sérieux : 15-20% des prompts.
Niveau 2 — Comparaison / Évaluation
L’utilisateur a identifié une catégorie, il compare des options concrètes.
Exemples de prompts : “Renault Scenic vs Peugeot 5008 électrique”, “Toyota Yaris avis sur la fiabilité long terme”, “meilleur rapport qualité-prix SUV compact électrique 2026”
Acteurs concernés : constructeurs, presse spécialisée, comparateurs, plateformes VO.
Enjeu GEO : être cité avec des arguments différenciants et des données chiffrées. Ici, la qualité de la citation compte plus que la mention : être cité “en premier, avec des chiffres” vs “en dernier, avec un ‘mais’” fait toute la différence.
L’étude de Princeton sur le GEO (Generative Engine Optimization) montre que l’ajout de statistiques et de citations de sources pertinentes peut augmenter la visibilité dans les réponses génératives de 40%.
Volume estimé dans un audit sérieux : 25-30% des prompts.
Niveau 3 — Intention d’achat / Conversion
L’utilisateur est prêt à passer à l’acte. Il cherche où et comment acheter.
Exemples de prompts : “meilleur prix Peugeot e-208 en ce moment”, “concessionnaire Kia sérieux région parisienne”, “vendre ma Clio 5 rapidement meilleur prix”
Acteurs concernés : concessionnaires, plateformes VO, agrégateurs de prix.
Enjeu GEO : être la solution recommandée pour passer à l’action. Selon l’étude Ekho (février 2026), 30% des acheteurs de véhicules ont utilisé l’IA lors de leur recherche — plus du double des marketplaces traditionnelles (12,7%).
Les acheteurs passant par l’IA montrent une intention d’achat plus élevée et plus précoce.
Selon Cars.com (novembre 2025), 97% des utilisateurs IA affirment que la réponse influencera leur décision d’achat.
Volume estimé dans un audit sérieux : 25-30% des prompts.
Niveau 4 — Post-achat / Fidélisation
L’utilisateur possède déjà un véhicule. Il cherche à l’entretenir, le réparer, le comprendre.
Exemples de prompts : “révision 208 1.2 PureTech 100 à 60 000 km que faire”, “causes de la climatisation ne souffle plus froid sur un Scenic”, “meilleur centre auto pour contrôle technique à la Part-dieu à Lyon”, “quelle huile pour une Golf 7 1.4 TSI”, “quel est le prix du changement d’embrayage sur une Clio 4”
Acteurs concernés : centres auto, équipementiers, fabricants de pièces, constructeurs (SAV).
Enjeu GEO : être la réponse experte de référence sur des problématiques techniques précises. C’est ici que le volume de requêtes est le plus élevé et le plus régulier (contrairement aux requêtes d’achat, qui sont ponctuelles), et que la conversion locale est la plus directe.
Volume estimé dans un audit sérieux : 25-30% des prompts.
Ce que cela implique pour les audits GEO / AEO
Un audit de visibilité IA sans cette segmentation par maturité est aveugle : il ne distingue pas les requêtes à fort enjeu commercial des requêtes informationnelles sans valeur transactionnelle directe.
Pour chaque acteur, le mix de prompts doit être pondéré selon son business model :
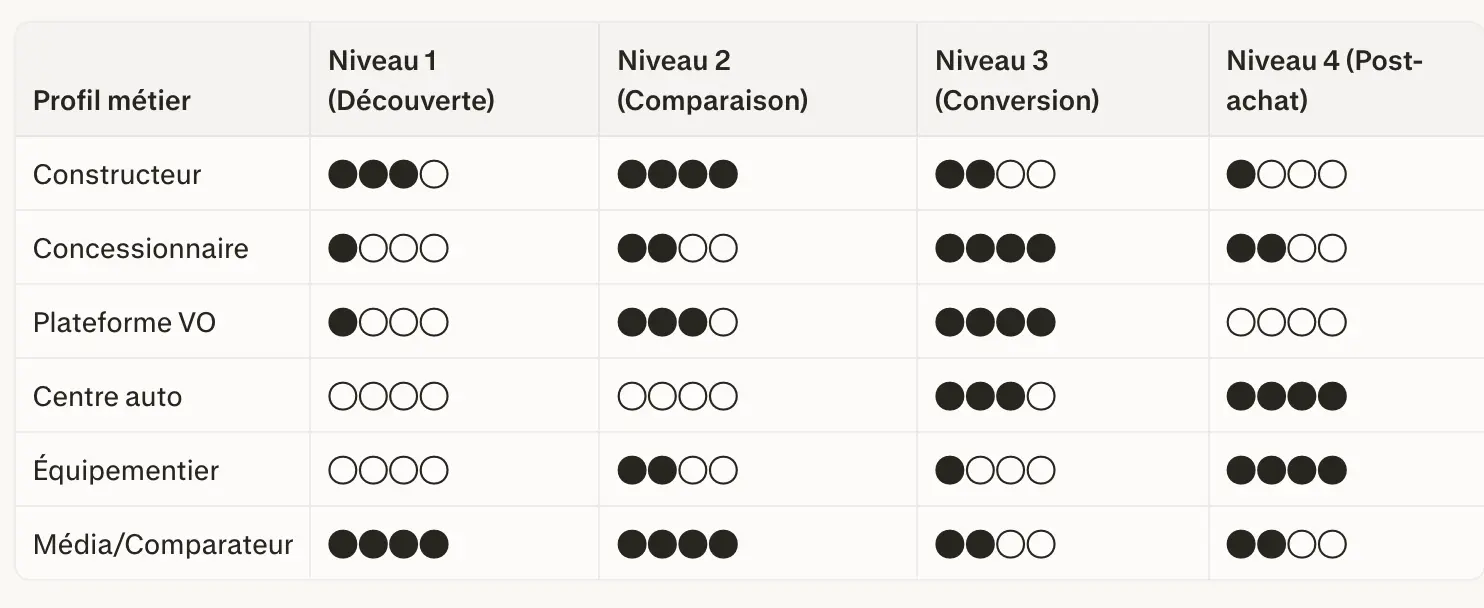
Un centre auto n’a aucun intérêt à surveiller sa visibilité au niveau 1.
Un constructeur n’a quasiment aucun intérêt au niveau 4.
Les 575 prompts de l’étude Uplix ne font pas cette distinction — ils ne le peuvent pas, puisque l’étude ne connaît pas le business model de celui qui la lit.
Ce qu’un vrai audit de visibilité IA devrait contenir
Les limites identifiées ci-dessus ne sont pas des critiques théoriques — elles ont des conséquences directes sur la qualité des décisions marketing.
Voici un cadre méthodologique en 5 étapes, construit pour servir réellement les décideurs automobile.
Étape 1 : Définir le profil métier avec précision
Ce que font les études superficielles : “automobile” comme verticale unique, benchmarking de constructeurs.
Ce qu’un audit sérieux fait : “réseau de centres auto en franchise, 200 points de vente, positionnement entrée/milieu de gamme, marché français, opérations principales : révision, pneumatiques, freinage, climatisation.”
Pourquoi : le profil métier détermine tout le reste — le corpus de prompts, les concurrents à benchmarker, les LLM à tester, et les KPI à suivre.
Comme le formule HubSpot dans son analyse des tendances AEO 2026, la découverte dans les moteurs de réponse est “intent-driven and contextual” — comprendre les micro-intentions de l’audience cible est le prérequis à toute optimisation.
Étape 2 : Cartographier les prompts par maturité et par persona
Ce que font les études superficielles : sélection de prompts par popularité ou facilité de mesure, sans segmentation par intention.
Ce qu’un audit sérieux fait : construction d’un corpus de requêtes représentatives des vrais usages, segmentées par les 4 niveaux de maturité, pondérées selon le business model de l’acteur audité.
Pourquoi : un prompt ChatGPT moyen fait 70 mots (OWDT) — c’est une question contextualisée, pas un mot-clé.
Les requêtes réelles des utilisateurs IA ressemblent à “je cherche un centre auto fiable à Lyon pour la révision de ma Peugeot 208 de 2021, avec 58 000 km” — pas à “révision auto Lyon.”
Étape 3 : Tester sur plusieurs LLM
Ce que font les études superficielles : ChatGPT uniquement (via API).
Ce qu’un audit sérieux fait : ChatGPT, Perplexity et Gemini au minimum, idéalement via l’interface web (et non via API).
Pedro Dias (Visively) détaille pourquoi : les interfaces web appliquent des system prompts cachés, déclenchent automatiquement la navigation web, et disposent de fonctionnalités (code execution, browsing) absentes des API.
Les résultats API ne sont pas transposables à l’expérience utilisateur réelle.
Pourquoi : avec 77,97% du trafic IA mondial pour ChatGPT, 15,10% pour Perplexity et 6,40% pour Gemini, ne tester qu’un seul LLM revient à n’auditer qu’un tiers du marché.
Et les visiteurs référés par Gemini passent 6 à 7 minutes par session — bien plus que les visiteurs organiques Google — ce qui signifie que l’engagement post-citation varie selon le LLM.
La donnée la plus parlante : 90% des pages citées par ChatGPT se classent en position 21 ou au-delà sur Google.
Un bon référencement Google ne garantit absolument pas une bonne visibilité IA — et inversement. Ce sont deux jeux différents avec des règles différentes.
Étape 4 : Mesurer la qualité, pas seulement la quantité
Ce que font les études superficielles : taux de visibilité brut (nombre de mentions / nombre de prompts).
Ce qu’un audit sérieux fait : analyse qualitative multicritère :
- Contexte de citation : la marque est-elle recommandée, mentionnée, ou citée avec réserve ?
- Position dans la réponse : première mention, milieu de liste, ou dernier cité avec un “mais” ?
- Présence de données chiffrées : le LLM cite-t-il des prix, des spécifications techniques, des métriques de fiabilité ?
- Tonalité : recommandation explicite vs mention conditionnelle vs mise en garde ?
Pourquoi : selon Yale (PNAS Nexus, mars 2026), les nuances de formulation des LLM influencent les opinions des utilisateurs même quand le contenu est factuellement exact.
Le cadrage narratif — être présenté comme “le leader fiable” vs “une option parmi d’autres” — a un impact mesurable sur la perception et la décision.
Étape 5 : Établir une baseline concurrentielle cohérente
Ce que font les études superficielles : comparer Toyota, Renault, Peugeot, Volkswagen et Mercedes-Benz dans un classement unique.
Ce qu’un audit sérieux fait : définir les concurrents par rapport aux acteurs qui concourent réellement pour les mêmes requêtes.
Pourquoi : comparer Norauto à Toyota dans un baromètre de “visibilité automobile” n’a aucun sens. La compétition IA doit être définie par le type de prompt :
- Sur “meilleure voiture familiale électrique” → Toyota vs Renault vs Volkswagen
- Sur “meilleur concessionnaire Toyota Lyon” → Jean Lain vs Autosphere vs SIVAM
- Sur “révision Peugeot 208 prix” → Norauto vs Midas vs Feu Vert vs garage indépendant
- Sur “batterie 12V Renault Zoe” → Oscaro vs Yakarouler vs Amazon vs site constructeur
Chaque concurrence est un micro-marché distinct, avec ses propres règles de citation et ses propres sources de confiance.
Ce que les directeurs marketing doivent exiger
La multiplication des outils de tracking de visibilité IA et des études sectorielles crée un paradoxe : plus il y a de données disponibles, moins il est facile de savoir lesquelles comptent.
Voici cinq exigences concrètes pour ne pas investir sur la base de métriques trompeuses.
1. Exiger la liste complète des prompts utilisés.
Si une étude ne publie pas son corpus de prompts, elle ne peut pas être auditée ni reproduite.
C’est un minimum de rigueur méthodologique. Un taux de visibilité de 52% ne signifie rien sans savoir comment les 575 prompts ont été sélectionnés.
2. Vérifier que les concurrents benchmarkés sont les vrais concurrents métier.
Un réseau de centres auto ne concourt pas contre Toyota — il concourt contre Midas, Feu Vert et le garage indépendant du quartier.
Tout baromètre qui ne segmente pas par profil métier est, au mieux, un outil de culture générale.
3. Demander la couverture multi-LLM.
Toute étude limitée à un seul moteur IA est structurellement biaisée.
Avec seulement 11% de chevauchement de domaines cités entre plateformes, optimiser pour ChatGPT seul revient à optimiser pour un tiers du marché en ignorant les deux autres.
4. Exiger la segmentation des prompts par niveau de maturité.
Un mélange de prompts découverte, comparaison, conversion et post-achat produit des moyennes sans valeur décisionnelle.
Demander la répartition permet de savoir si l’étude mesure ce qui compte pour votre business model.
5. Distinguer ce qui est mesurable de ce qui est actionnable.
Pedro Dias (Visively) résume bien l’enjeu : les outils de tracking IA sont raisonnablement utiles pour vérifier la reconnaissance d’entité et auditer l’exactitude factuelle.
Ils sont en revanche incapables de produire des “classements par mot-clé” granulaires ou des métriques de “part de voix” fiables, parce que les modèles IA sont non-déterministes et que les résultats varient en fonction du contexte utilisateur, de la version du modèle et du phrasé du prompt.
Conclusion : la pertinence contre la notoriété
Le GEO automobile n’est pas une discipline de notoriété — c’est une discipline de pertinence contextuelle.
Toyota n’a pas besoin d’un baromètre pour savoir qu’elle est visible sur les LLM.
Elle est visible parce qu’elle est Toyota — parce que des millions de pages la mentionnent dans toutes les langues depuis 25 ans.
Celui qui a besoin de mesurer sa visibilité IA, c’est le réseau de centres auto qui veut savoir si ChatGPT le recommande quand un propriétaire de Peugeot 208 cherche où faire sa révision à Lyon.
C’est la plateforme VO qui veut savoir si Perplexity la cite quand un utilisateur demande où vendre sa voiture rapidement.
C’est l’équipementier qui veut savoir si Gemini connaît ses références de compatibilité.
Ces acteurs sont les grands absents des baromètres actuels.
Et ce sont précisément eux qui ont le plus à gagner — ou à perdre — dans la transition vers les moteurs de réponse IA.
Les données existent pour faire mieux.
30% des acheteurs de véhicules utilisent déjà l’IA dans leur parcours d’achat (Ekho).
97% de ceux qui l’utilisent disent que ça influence leur décision (Cars.com).
La recherche IA générative croît 165 fois plus vite que la recherche traditionnelle. La question n’est plus de savoir si l’AEO compte — c’est de savoir si on le mesure correctement.
Et la pertinence, par définition, ne se mesure pas avec un seul prompt envoyé à un seul LLM.
Vous souhaitez progresser ?
J’accompagne les entreprises du secteur automobile dans leur transition vers l’IA et le GEO, en mettant en place des stratégies de contenu IA et/ou en formant les équipes. Christophe Potron → Contactez-moi
Odowatch est le media de veille GEO et IA d’Odopass, dédié aux professionnels de l’aftermarket automobile. Retrouvez chaque semaine nos analyses sur odowatch.substack.com
Sources citées dans cet article :
- Yext — AI Visibility in 2025 (6,8M citations)
- Qwairy / Whitehat SEO — 118K réponses IA analysées
- Profound — AI Platform Citation Patterns (680M citations)
- Visively — Understanding AI Visibility: Fundamentals and Limits
- Seer Interactive — What Drives Brand Mentions in AI Answers
- Ekho — 2026 AI Vehicle Research Study
- CarGurus — Consumer Insights Report 2025
- Cars.com — AI in Car Shopping Survey
- Cox Automotive — Car Buyer Journey Study 2025
- Kahn Media — Shifting Gears: 2025 Aftermarket Purchasing Trends
- Forbes — Answer Engine Optimization: What Brands Need to Know
- Princeton — GEO: Generative Engine Optimization (arXiv)
- Yale / PNAS Nexus — AI’s Hidden Bias in Chatbots
- HubSpot — AEO Trends 2026
- SE Ranking — AI Traffic Study 2025
- Search Engine Land — Structured Data and AI Visibility
- Hrizn — Structured Data for Dealerships
- Grand View Research — France Automotive Aftermarket
- PCFitment — Automotive Search Behavior
- OWDT — What Is Answer Engine Optimization
- Adpearance — AEO for Automotive Dealers
- RankScience — AI Citations vs Mentions
- Uplix / Meteoria — Baromètre Auto: Analyse de Visibilité IA (Oct. 2025 – Jan. 2026)



